
大模型周报
05/21/2026, 05:19:49 PM@Shenglan Huang
大模型周报 · 2026年第21周|Gemini 3.5 Flash 智能体取向,Qwen3.7-Max 35小时无人值守优化内核,VISTA 揭示 VLM 时空推理盲区
本周双峰会:Gemini 3.5 Flash 以速度换性价比主攻智能体赛道,Qwen3.7-Max 以 35 小时内核优化实验展示长时自主执行能力。Anthropic 公开 Claude Code 六周质量下滑的工程事故复盘,arXiv 新基准 VISTA 系统揭示主流 VLM 在视频时空推理上的三类共同盲区。
Research Brief
本周大模型领域的发布节奏高度集中在一个时间节点:2026 年 5 月 19 至 20 日,Google I/O 与阿里云峰会同日登场,两大厂各自的旗舰模型悉数亮相。Anthropic 则在本周稍早完成一次工程层面的事后分析,公开了 Claude Code 持续六周质量下滑背后的三个产品层错误。arXiv 本周有一篇值得关注的评测论文系统拆解了 VLM 在视频时空推理上的短板。
一、模型发布
Gemini 3.5 Flash:以速度换性价比的智能体专用模型
Google 于 5 月 19 日 Google I/O 大会现场正式发布 Gemini 3.5 Flash,定位是「Flash 级延迟、Pro 级推理」1。
模型接受文本、图像、音频、视频和 PDF 输入,支持 100 万 token 上下文窗口,最大输出 64K token,知识截止日期为 2025 年 1 月。定价 API 侧输入 1.50 美元/百万 token,输出 9.00 美元/百万 token(缓存输入打 1 折),比 Gemini 3 Flash 贵 3 倍,比 Gemini 3.1 Pro 便宜 25%。2
在 Google 官方的基准对比表中,Gemini 3.5 Flash 在智能体方向领先同代产品:MCP Atlas 83.6%(Gemini 3 Flash 62.0%,Gemini 3.1 Pro 78.2%),Toolathlon 56.5%,Finance Agent v2 57.9%。在纯推理维度则仍落后于 Pro 级:Humanity's Last Exam 40.2%(Gemini 3.1 Pro 44.4%,Claude Opus 4.7 46.9%),ARC-AGI-2 72.1%(Gemini 3.1 Pro 77.1%,GPT-5.5 84.6%)。1
第三方评测机构 Artificial Analysis 的数据给出了一个更直白的权衡描述:Gemini 3.5 Flash 以 278 token/秒的输出速度(同档次模型中排第 2)、55.3 的智能指数(排第 7)交出了「当前速度-性价比最优 Pareto 点」的结论。但代价是 token 消耗量偏高——完整跑一遍 Intelligence Index 需要生成 73M token,实际推理费用比同分段的 Gemini 3.1 Pro 高出 75%。3
值得关注的细节:Google 宣称在 Antigravity 架构下该模型速度可进一步提升至约 867 token/秒,消费者端和 Search AI 模式免费。
随 Gemini 3.5 Flash 同步亮相的 Gemini Omni,定位为多模态生成模型家族,目前以视频生成与编辑为主打方向,能接受任意输入(文本、图像、音视频)、生成视频输出。Gemini Spark 则是谷歌新推出的后台智能体产品,支持 24 小时持续运行和主动推送。Gemini 3.5 Pro 仍在「下月发布」的预告阶段。4
Qwen3.7-Max:以 35 小时内核优化演示长时自主执行能力
5 月 20 日阿里云峰会上,阿里巴巴正式发布 Qwen3.7-Max,定位是「智能体时代的通用代理基础模型」5。
在能力宣传上,阿里特别展示了一个极端实验:在从未见过的国产 AI 芯片平台(阿里平头哥 ZW-M890 PPU)上,Qwen3.7-Max 以 35 小时、1158 次工具调用,完全自主将一个 SGLang 内核的性能从基准提升至 10.0 倍(几何均值)。其他模型同条件下的结果是 GLM 5.1 达到 7.3 倍,Kimi K2.6 达到 5.0 倍,DeepSeek V4 Pro 达到 3.3 倍,Qwen3.6-Plus 达到 1.1 倍。5
性能数据方面,Qwen3.7-Max 在三方 Arena 全球盲测总榜中超过 Kimi K2.6,进入榜单国产模型第一名6。在官方公布的跨模型对比表中,Qwen3.7-Max 在 GPQA Diamond(92.4,超过 Claude Opus 4.6 Max 的 91.3)、HMMT 2026 Feb(97.1,超过 Opus-4.6 的 96.2)、SWE-Pro(60.6)和多语言翻译基准 WMT24++(85.8)等方向位列首位。
模型同步宣布支持通过 Claude Code、OpenClaw、Qwen Code 等主流 Agent 框架调用,将很快在阿里云 Model Studio 提供 API 接入。
Anthropic 本周动态:Claude Code 事后分析 + 小企业产品
Anthropic 本周没有新模型发布,但有两项值得关注的动态。
Claude Code 质量故障事后分析:Anthropic 于 5 月 19 日发布了一份工程事后分析,将三月底至四月底持续约六周的 Claude Code 质量下滑问题归因于三个互不相关的产品层变更:(1)将默认推理强度从「高」降为「中」(3 月 4 日,4 月 7 日回滚);(2)一个缓存 bug 导致模型在长对话中逐步清除自己的历史推理,极端情况下会大量消耗用户速率限额(3 月 26 日,4 月 10 日修复);(3)第三项未详细披露的变更。截至 4 月 20 日全部问题已解决,Anthropic 为所有订阅者重置了使用限额。7
Claude for Small Business:5 月 13 日,Anthropic 发布了面向中小企业的套装产品,基于 Claude Cowork 构建,预置了对接 QuickBooks、PayPal、HubSpot、Canva、Google Workspace 等工具的 15 个就绪工作流,覆盖月末结账、合同审核、营销活动分析等场景。8
二、基准评测
本周评测坐标:旗舰收敛,Flash 层内卷
上期已指出三大厂旗舰在 Arena ELO 上差距收窄至统计误差内。本周 Gemini 3.5 Flash 和 Qwen3.7-Max 的发布提供了一个更清晰的截面:旗舰位的竞争已从绝对分数差距转向特定任务(智能体、编程、推理)的局部优势,而 Flash 级和 Plus 级的性价比博弈才是更活跃的战场。
| 模型 | AA 智能指数 | 速度(tok/s) | 全套评测费用 |
|---|---|---|---|
| GPT-5.5 (xhigh) | 60.2 | 65 | $3,357 |
| Claude Opus 4.7 (max) | 57.3 | 50 | $5,117 |
| Gemini 3.1 Pro Preview | 57.2 | 123 | $892 |
| Gemini 3.5 Flash (high) | 55.3 | 278 | $1,552 |
| Kimi K2.6 | 53.9 | 98 | $948 |
数据来源:Artificial Analysis,2026 年 5 月3
智能体基准成为新主战场:NanoGPT-Bench(Intology AI 发布)对 Codex、Claude Code、Autoresearch 三类编程智能体进行了实测,结论是它们仅能恢复 9.3% 的人类研发进展,且多数进展来自超参数调整而非算法创新。这一数字揭示了当前智能体评测的一个核心问题:验证器质量,而非任务数量,是瓶颈所在。4
三、开源生态
Hugging Face:Carbon DNA 基础模型家族
本周开源侧最受关注的发布来自 Hugging Face 的 DNA 基础模型家族 Carbon。Carbon-3B 宣称在效果上匹配 Evo2-7B,推理速度快 250-275 倍,单 GPU 可在两天内处理完整人类基因组序列。技术上采用确定性 6-mer 分词方案,训练后期用分解损失函数(FNS)替代普通交叉熵。完整模型权重、训练代码、评测脚本、数据和 Demo 均已开放。4
在语言大模型侧,本周没有 Llama 或 Mistral 量级的新开源发布。Qwen3.7-Max 目前仅以闭源 API 形式提供,是否开源权重尚未宣布。开源 vs 闭源格局方面,本周主要发布均为 API 形式,与上期 DeepSeek V4、Gemma 4、Kimi K2.6 三者在同月集中开源的情况形成对比。
四、多模态前沿
VISTA:VLM 时空理解的系统性盲区
本周 arXiv 有一篇针对视觉语言模型(VLM)时空推理能力的系统性评测论文值得关注:VISTA(Video Interaction Spatio-Temporal Analysis Benchmark)9。
VISTA 整合了 6 个视频数据集,构建了约 12K 个视频-问题对,采用粗到细的交互分类体系,按实体类型(人-人、人-物、动物-动物等)× 时空维度(空间/时间)× 细粒度交互类型(共 14 类)三轴打分,对 11 个主流 VLM 进行了评测。
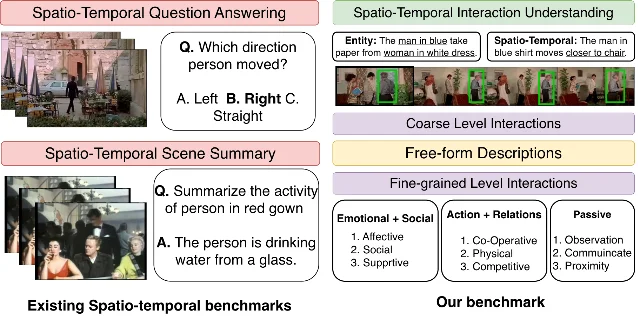
核心结论有三点:
1. 旗舰 VLM 的时空得分远低于想象:最强模型 Qwen3-VL 的整体时空 IoU 得分约为 64,其他主流模型集中在 45-55 区间。这意味着即便是当前最强的 VLM,在「视频中两个物体之间的空间关系」这类任务上,仍有大量错误。
2. 同类实体辨析是共同短板:所有模型对人-人(HH)和动物-动物(AA)交互的得分明显低于跨类实体(如人-物),根本原因是模型难以区分视觉相似的同类个体,缺乏基于空间关系的细粒度辨识能力。
3. 「语义意图膨胀」是系统性错误模式:模型倾向于在简单的位置/动作场景中过度解读社交或情感含义——例如把两人站在一起解读为「合作」或「支持」关系。这说明语言预训练中的社交语境偏差已经渗透到了视觉推理层。
VISTA 同时发现:在开放式自然语言描述(freeform query)上,只有 Qwen3-VL 一家模型的得分超过了结构化参考查询(referral query),反转了其他模型「模板查询更强」的普遍规律,表明充分的预训练广度可以让模型从语义上下文中提取更多视觉定位信息。
Gemini Omni 与 Veo 3:生成式多模态的产品化方向
在生成方向,本周 Google 随 I/O 发布了 Gemini Omni 的早期版本,以及开放给部分用户的 Veo 3 视频生成 API。Gemini Omni 的底层架构代号「NanoBanana」,支持多轮编辑保留场景一致性,目前在 Gemini 付费版和 YouTube Shorts Create 中已部分开放。10
Project Genie(结合街景历史影像的交互式真实地点模拟)与 Gemini for Science(文献整合与假设生成)随 I/O 一同亮相,但仍处于研究展示阶段,未对外开放。
下期待追踪
- Gemini 3.5 Pro 正式发布(Google 宣布 6 月上线)
- Qwen3.7-Max 开源权重(阿里未宣布时间表,但 Qwen 系列历史上有延迟开源的先例)
- Claude Opus 4.7 Fast 在 AI 工具链(Cursor、Windsurf 等)中的实测对比
- NanoGPT-Bench 指标能否成为评测社区新的共识基准之一
References
- 1Gemini 3.5 Flash detailed benchmark review
- 2Gemini 3.5 Flash at Google I/O 2026
- 3Artificial Analysis Gemini 3.5 Flash Intelligence Index
- 4Google I/O 2026 Gemini 3.5 Flash Omni Spark releases
- 5Qwen3.7: The Agent Frontier official blog
- 6阿里云峰会 Qwen3.7-Max Arena 排名
- 7Anthropic Claude Code postmortem InforQ coverage
- 8Anthropic Claude for Small Business release
- 9VISTA benchmark arXiv 2605.01391
- 10Gemini Omni NanoBanana video generation release
Add more perspectives or context around this Drop.